Design of a job scheduler

From Wikipedia,
A job scheduler is a computer application for controlling unattended background program execution of jobs.
In the real world, we find lots of use cases of a job scheduler. For example,
- Run a script daily to generate reports
- Charge subscription of a user daily/monthly.
- Running of a payroll program
In this post, we’ll design and develop a job scheduler that can help us to scale in need.
Requirements
- A job can be scheduled for one time or multiple executions
- Results of job executions are stored and can be queried
There are also some non-functional requirements to think of
- Scalability: Thousands or even millions of jobs can be scheduled and run per day
- Durability: Jobs must not get lost
- Reliability: Jobs must not be executed much later than expected or dropped
- Availability: It should always be possible to schedule and execute jobs
- Jobs must not be executed multiple times (or such occurrences should be kept to a minimum)
Job service
First, we need to create a service to store the job metadata. For simplicity, we can make a rest service endpoint that will store the job information in storage.
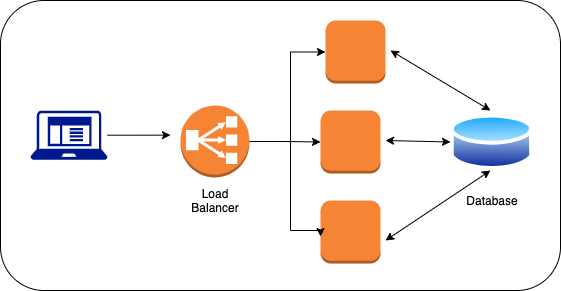
If we deploy our job service behind a load balancer then it can handle traffic load easily and store job metadata to the database.
Job execution
So far, we have job information stored in our database. Now, we need to run a background process to check when to start a job. Either we need to run cron-like process or use an event-driven strategy to have the same functionality.
The software utility cron also known as cron job is a time-based job scheduler in Unix-like computer operating systems. Users who set up and maintain software environments use cron to schedule jobs.
Cron internally uses crontab (Cron table) to run periodically schedule jobs. There are two ways to solve our problem with cron.
- Run a script periodically. This script will search all the jobs which match the criteria and executes them.
- For every job, add an entry to crontab to run jobs as scheduled. This solution is not scalable and not fault-tolerant as it has a dependency on the operating system.
We can run a script periodically to check if any jobs are eligible to execute. Some decisions need to be made to implement this.
- The job trigger time will not be exact. If a job has a trigger time just after the script run, then the job will wait until the next iteration.
- To reduce the job execution delay, the length of the period needs to be smaller and thus the resource will be busy with frequent execution.
Event-based trigger
Jobs can run based on a certain event. If we can create an event for each of the jobs, then at some event of execution time we can start our job.
Redis has an event called expiration event. Redis deletes a key after the time expires and throws an event to the subscriber channel.
1 | const { createClient } = require('redis'); |
For each job, we can create a key in Redis with appropriate expiration. After the time expired, we will get an event and run the appropriate trigger based on the task metadata.
Timing of Redis expired events
Keys with a time to live associated are expired by Redis in two ways:
- When the key is accessed by a command and is found to be expired.
- Via a background system that looks for expired keys in the background, incrementally, to be able to also collect keys that are never accessed.
There are some issues with this approach,
- There are no guarantees that the Redis server will be able to generate the expired event at the time the key time to live reaches the value of zero
- expired events are generated when the Redis server deletes the key and not when the time to live theoretically reaches the value of zero.
- Pub/Sub communication in a cluster, events notifications are not broadcasted to all nodes.
For Redis expiration, it runs these steps 10 times per second
- Test 20 random keys from the set of keys with an associated expire.
- Delete all the keys found expired.
- If more than 25% of keys were expired then starts again.
The accuracy of expiration of Redis
- For Redis 2.4, zero to one second
- Redis 2.6, the error is from 0 to 1 millisecond.
So, provided values look good to implement events in Redis.
Note: For the Redis cluster, to receive all keyspace events, we need to subscribe to each of the nodes.
Durability
If the event server crashes or execution fails, there is no way to track what happened or retry the same operation. There may be a running job going on, and the service can’t handle a new one.
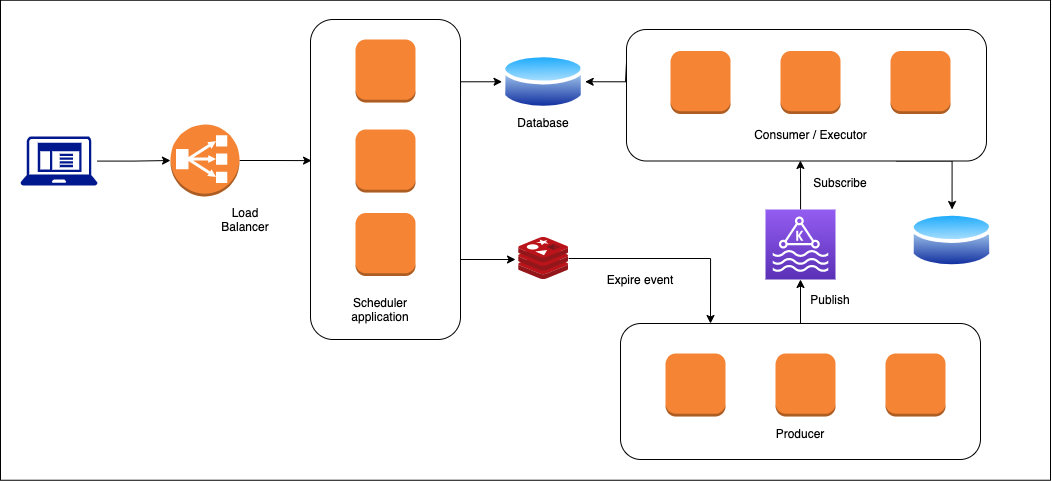
To solve these issues, we can add an extra layer of a queue. The generated event will publish to a topic in the Queue. We are using Kafka for this use case.
To test this, we can set up a Kafka using docker-compose.
1 | version: "3" |
A producer example to push events to our Kafka cluster.
1 | // producer.js |
A consumer can listent to a certain topic and handle execution based on type.
1 | // consumer.js |
The executor service will subscribe to a different topic and then act based on different properties.
Message duplication
These consumers can perform different tasks based on events. In our case, we need to ensure the executor service need to runs exactly once.
There are two different ways to solve this problem.
- Message broker support for duplication.
- Using a database with ACID properties
How do I get exactly once messaging from Kafka?
Exactly once semantics has two parts: avoiding duplication during data production and avoiding duplicates during data consumption.
There are two approaches to getting exactly once semantics during data production:
- Use a single-writer per partition and every time you get a network error check the last message in that partition to see if your last write succeeded
- Include a primary key (UUID or something) in the message and deduplicate on the consumer.
Database layer duplication handling
When a consumer gets the event to execute the task, it can use the locking benefit of a database system. The approach can be,
- Add an entry to a table with UNIQUE_KEY restriction, so that multiple entries can not be created with the same ID.
- Process execution tasks in transactions.
If the databases are in different locations or zone, then we need to ensure strong consistency in this approach. Otherwise, a different consumer from a different location will same entity and that will lead to another problem of conflict resolution.
Executor service
The last piece of our system is an executor service. The consumer can act as the executor service to run appropriate operations based on scheduler metadata.
From this service, the metadata of execution can be stored in a database for future queries.
Improvement
There are some improvements we can do to make our service better.
- If we can connect the event generation directly with the topic queue, then the producer service layer can be removed.
- Queue topics can be distributed with some criteria. This way consumers can be distributed with focused action groups.
- Database partition can be used based on need.
Please share improvement ideas or feedback on this.
About this Post
This post is written by Mahfuzur Rahman, licensed under CC BY-NC 4.0.