According to wikipedia, a cache is a hardware or software component that stores data so that future requests for that data can be served faster.
Benefits:
- Faster access of data in O(1)
- Computation complexity once for the first time
Types:
- Memory cache
- Database cache
- Disk cache, etc
In this post, we’ll go through the steps to create a in memory cache in java.
To create a cache, we can simply use a map / dictionary data structure and we can get the expected result of O(1) for both get and put operation.
But, we can’t store everything in our cache. We have storage and performance limits.
A cache eviction algorithm is a way of deciding which element to evict when the cache is full. To gain optimized benefits there are many algorithms for different use cases.
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
- First In First Out (FIFO)
- Last In First Out (LIFO) etc.
There are only two hard things in computer science, Cache invalidation and naming things. — Phil Karlton
In our design, we will use
- HashMap to get and put data in O(1)
- Doubly linked list
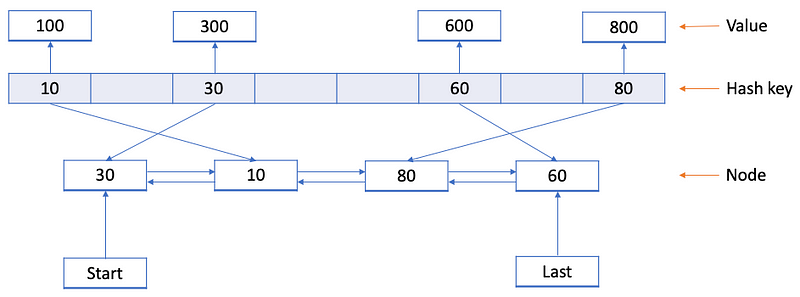 Cache implementation strategy
Cache implementation strategy
We are using doubly linked list to determine which key to delete and have the benefit of adding and deleting keys in O(1).
Initially we will declare a model to store our key-value pair, hit count and reference node to point previous and next node.
1 | public class CacheItem<K, V> { |
Now, we can outline our cache class with basic functionalities of get, put, delete and size.
1 | public class Cache<K, V> { |
We also included hit count and miss count to determine the performance of our cache.
Hit ratio = total hit / (total hit + total miss)
For our put method
- If key already exists, update the value
- Otherwise, If size exceeds capacity
- Delete existing node using appropriate strategy
- Add new node in the top
1
2
3
4
5
6
7
8
9
10public void put(K key, V value) {
CacheItem node = new CacheItem(key, value);
if(map.containsKey(key) == false) {
if(size() >= CAPACITY) {
deleteNode(first);
}
addNodeToLast(node);
}
map.put(key, node);
}
In our delete method
- Remove node from map
- Delete all references associated with that node.
1
2
3
4
5
6
7
8
9
10
11
12
13
14private void deleteNode(CacheItem node) {
if(node == null) {
return;
}
if(last == node) {
last = node.getPrev();
}
if(first == node) {
first = node.getNext();
}
map.remove(node.getKey());
node = null; // Optional, collected by GC
size--;
}
We can add node in the top. The last pointer will reference to the last inserted node.
1 | private void addNodeToLast(CacheItem node) { |
In our get method,
- Get data from map
- Increment the counter for that item. ( Useful for lease frequently used )
- Reorder the linked list.
1
2
3
4
5
6
7
8
9public V get(K key) {
if(map.containsKey(key) == false) {
return null;
}
CacheItem node = (CacheItem) map.get(key);
node.incrementHitCount();
reorder(node);
return (V) node.getValue();
}
Reorder is the key for this implementation. For different algorithm this reorder to delete method will change.
Least Recently Used (LRU)
Delete candidate is the oldest used entry.
- The latest accessed node will be at the last end along with newly added items. In this way, we can delete from the first easily.
1
2
3
4
5
6
7
8
9
10
11
12
13
14private void reorder(CacheItem node) {
if(last == node) {
return;
}
if(first == node) {
first = node.getNext();
} else {
node.getPrev().setNext(node.getNext());
}
last.setNext(node);
node.setPrev(last);
node.setNext(null);
last = node;
}
Least Frequently Used (LFU)
Delete candidate is the least accessed entry.
We have to sort items based on the frequency the nodes being accessed.
To avoid getting deleted, for each accessed items needs to reach top based on their frequency.
- Iterated a loop, which swaps the node if the frequency is greater than it’s next node frequency.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28private void reorder(CacheItem node) {
if(last == node) {
return;
}
CacheItem nextNode = node.getNext();
while (nextNode != null) {
if(nextNode.getHitCount() > node.getHitCount()) {
break;
}
if(first == node) {
first = nextNode;
}
if(node.getPrev() != null) {
node.getPrev().setNext(nextNode);
}
nextNode.setPrev(node.getPrev());
node.setPrev(nextNode);
node.setNext(nextNode.getNext());
if(nextNode.getNext() != null) {
nextNode.getNext().setPrev(node);
}
nextNode.setNext(node);
nextNode = node.getNext();
}
if(node.getNext() == null) {
last = node;
}
}
This way, there is an edge case where, after adding items that require delete from the start can cause deletion of the high frequency node.
To solve this issue, we need to add nodes pointing our first node for least frequently accessed.
1 | private void addNodeToFirst(CacheItem node) { |
First In First Out (FIFO)
Delete candidate is the first node.
- To add node we will use addNodeToLast
- Reordering is not required.
- Delete node from first
Last In First Out (LIFO)
Delete candidate is the last node.
- To add node we will use addNodeToLast
- Reordering is not required.
- Delete node from last
Questions:
- We can use array /ArrayList to solve the same issue with simplified coding.
Yes, it would be simpler. The aspects for not using,
- ArrayList has complexity of insertion and deletion of O(n) in worst case
- To search from there list, the worst case complexity would be O(n)
- We could have used the LinkedList instead of ArrayList.
Once again, yes. LinkedList had the benefit for adding and removing node at O(1). The aspects for not using,
- We will still face the searching complexity of O(n)
- For LFU, we are having a complexity of O(n) in reordering method.
Yes, unfortunately.
- I’m reordering here after each get request, which increases the complexity for each get. For post heavy system, this approach will benefit.
- It can be done at the moment of deletion. This way the complexity will increase at the time of putting data. For get heavy system, this approach will benefit more.
I have came up a solution with this so far. Please suggest any better idea.
- We are using HashMap. It can have the issue of hash collision. Then the performance will not be O(1) as mentioned.
Absolutely.
- It’s always recommended to use better hash function that cause less collision.
- Make sure our load factor remains 0.75 or less.
- If the load factor is more than default or provided one, from Java 8 HashMap automatically increase the size and rehash the full structure.
- From Java 8, the collision also being handled by using balanced tree to obtain O(log n) performance.
I’ve written a post with implementation and explanation HashMap Implementation for Java.
- Is this implementation thread safe?
No. To be thread safe
- We can use ConcurrentHashMap instead of HashMap
- Use synchronized block
- How to add time based eviction strategy to auto delete items?
No. To implement this, we need to run a timer thread to define which items are eligible for eviction and perform deletion operation.
About this Post
This post is written by Mahfuzur Rahman, licensed under CC BY-NC 4.0.